Meta-learning trains models to adapt quickly across many tasks, not just perform well once. The paper shows how this approach improves domain adaptation, personalization, federated and continual learning, and in-context learning. It argues meta-learning should be treated as infrastructure, enabling adaptable, resilient, and governable AI systems in real-world settings globally.
From transfer to preparation
Over the last decade, machine learning has quietly shifted its deepest concern. Accuracy on benchmark tasks has become less decisive than the capacity to adapt. Models are now judged not only by how well they perform on a fixed distribution but by how efficiently they absorb change, scarcity, heterogeneity, and surprise. In this context, meta-learning has moved from a theoretical curiosity to a structural ambition for artificial intelligence systems that must operate across domains, organizations, and regulatory regimes.
Anna Vettoruzzo’s doctoral thesis, Advancing Meta-Learning for Enhanced Generalization Across Diverse Tasks, represents one of the most systematic attempts to consolidate this ambition into an extensible research program. Rather than proposing a single algorithmic breakthrough, the thesis traces how meta-learning operates as a connective substrate across multiple subfields: domain adaptation, multimodal task distributions, federated learning, continual learning, time series modelling, and unsupervised representation via in-context learning. For industry and policy leaders, the relevance lies not in any isolated method, but in the structural claim that meta-learning reframes how learning systems should be designed, deployed, and governed.
This essay develops that claim by reading Vettoruzzo’s work as a map of where generalization is being redefined, and where institutional actors should expect friction, leverage, and standardization pressure to emerge.
Meta-learning as a systems-level abstraction
At its core, meta-learning proposes a reversal of optimization priorities. Instead of training a model to master a single task, the model is trained to acquire a prior that enables rapid specialization. Vettoruzzo formalizes this via a clear task-centric framework: tasks are sampled from an underlying distribution, each with its own data generating process and loss function, and learning consists of optimizing parameters that encode shared structure across tasks.
This abstraction is deceptively simple. It collapses distinctions between what are often treated as separate engineering problems: few-shot learning, transfer learning, hyperparameter optimization, and even architecture selection. In industrial terms, meta-learning suggests that learning infrastructure should be designed less as a pipeline and more as a capability that amortizes adaptation costs across time and clients.
This perspective aligns with trends visible in large-scale industrial systems. Google DeepMind’s early work on Model-Agnostic Meta-Learning and optimization-based adaptation, Meta’s investment in scalable few-shot personalization, and OpenAI’s exploration of in-context learning using transformer architectures all indicate that meta-learning is no longer confined to academic benchmarks. However, Vettoruzzo’s contribution is to show, with methodological rigor, that these developments are not isolated tricks but instances of a broader organizing principle.
Domain adaptation and the economics of unlabelled data
One of the most immediately practical contributions of the thesis lies in its integration of meta-learning with unsupervised domain adaptation. In many regulated or industrial environments, labelled data is scarce not because data does not exist, but because labelling is costly, sensitive, or jurisdictionally constrained. Sensors drift, environments change, and models degrade silently.
By framing domain adaptation as a meta-learning problem, Vettoruzzo shows how models can be trained to anticipate domain shifts and adapt using minimal or unlabelled data from the target domain. This is not merely a performance gain. It alters the economics of deployment. Systems become less brittle to geographical distribution, supplier variation, or user-specific conditions.
For sectors such as manufacturing, energy, logistics, and healthcare, where retraining pipelines can be operationally expensive or slow to certify, meta-learned adaptation offers a pathway to resilience without constant human intervention. From a policy standpoint, this also raises questions about validation and auditability: if adaptation is learned rather than engineered, what constitutes a stable system, and how should its boundaries be regulated?
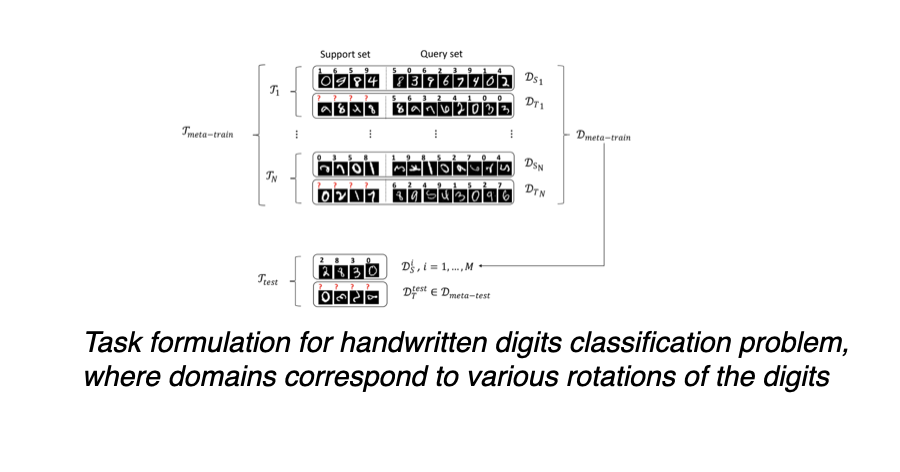
Multimodal task distributions and heterogeneity at scale
A recurring assumption in early meta-learning research was that tasks differ smoothly. Vettoruzzo dismantles this assumption by addressing multimodal task distributions, where tasks are drawn from distinct, unlabeled modes that may correspond to domains, environments, or user populations.
Her work on multiple sets of meta-parameters and learned task representations acknowledges a reality familiar to large organizations: heterogeneity is structural, not noise. A single global prior is often insufficient. Instead, systems must infer which mode of experience they are operating in, without explicit supervision.
This insight has direct implications for platforms serving diverse global markets. Recommendation systems, fraud detection, human activity recognition, and personalization pipelines all face fragmented task landscapes shaped by culture, infrastructure, and regulation. Meta-learning methods that internalize this fragmentation reduce reliance on brittle rule-based segmentation and manual model branching.
Companies such as Amazon, ByteDance, and Netflix already operate internal systems that route data through differentiated learning pathways. Vettoruzzo’s work suggests that these architectures can be formalized and generalized, moving from ad hoc engineering solutions toward principled meta-learning frameworks.
Personalized federated learning and institutional trust
Among the most policy-relevant sections of the thesis is the integration of meta-learning with federated learning. Federated learning addresses privacy and data sovereignty by keeping data local, but it struggles with personalization and statistical heterogeneity across clients.
Vettoruzzo proposes a meta-learned personalization mechanism that modulates shared models based on contextual client information, without violating privacy constraints. This approach reframes federated learning not as a compromise between performance and privacy, but as an opportunity to learn adaptation strategies that respect both.
This is particularly salient for public sector deployments and regulated industries, where federated learning is often positioned as a compliance mechanism rather than a performance strategy. Meta-learning introduces a third axis: adaptability. It suggests that institutions can design systems that are locally responsive while remaining globally coordinated.
Standardization bodies such as ISO, IEC, and ETSI are beginning to address federated learning and distributed AI governance. Meta-learning challenges them to consider not just model aggregation protocols, but learned adaptation dynamics as objects of standardization and audit.
Continual learning without forgetting and operational longevity
The thesis also engages with one of the oldest difficulties in machine learning: catastrophic forgetting. In operational environments, models must integrate new information without erasing prior competencies. Vettoruzzo’s meta-learned attention-based optimizer selectively updates parameters, effectively learning how to learn continuously.
For industry, this offers a reframing of model lifecycle management. Instead of discrete retraining events and versioning regimes, systems can evolve incrementally while preserving institutional memory. This has clear value in robotics, autonomous systems, and long-lived industrial controllers.
From a governance perspective, continual meta-learning complicates accountability. When learning dynamics are themselves learned, tracing causality becomes harder. Yet ignoring these dynamics risks deploying systems that degrade unpredictably over time.
Unsupervised meta-learning and the rise of in-context adaptation
Perhaps the most forward-looking contribution of the thesis is its exploration of unsupervised meta-learning via in-context learning. Drawing on the behaviour observed in large transformer models, this work constructs tasks implicitly from unlabelled data and learns to generalize without explicit adaptation steps.
This line of research blurs the boundary between training and inference. It suggests that models can internalize learning procedures that are executed purely through context, aligning with capabilities observed in large language models deployed by OpenAI, Anthropic, and others.
For policy and industry leaders, this raises fundamental questions about evaluation and control. If models adapt through context rather than parameter updates, traditional notions of retraining, certification, and version control become inadequate. Meta-learning thus anticipates governance challenges that are only now becoming visible at scale.
Meta-learning as infrastructure, not technique
Vettoruzzo’s thesis does not claim to solve general intelligence. Its significance lies elsewhere. It treats meta-learning as an infrastructural layer that reorganizes how learning systems interact with data, tasks, users, and time. By embedding adaptation into the learning objective itself, meta-learning shifts emphasis from performance maximization to adaptability optimization.
For industry leaders, this framing encourages investment in learning systems that age gracefully, personalize responsibly, and adapt cheaply. For policymakers, it signals the need to regulate not just models and data, but learning dynamics over time.
Meta-learning is often described as learning to learn. The deeper implication surfaced by this work is that institutions must learn how their systems learn, and decide which forms of adaptation they are willing to authorize.
References
Vettoruzzo, A. (2025). Advancing meta-learning for enhanced generalization across diverse tasks. Halmstad University Press.
Vettoruzzo, A., Bouguelia, M. R., Vanschoren, J., Rögnvaldsson, T., & Santosh, K. C. (2024). Advances and challenges in meta-learning: A technical review. IEEE Transactions on Pattern Analysis and Machine Intelligence, 46, 4763–4779.
Vettoruzzo, A., Bouguelia, M. R., & Rögnvaldsson, T. (2024). Meta-learning for efficient unsupervised domain adaptation. Neurocomputing, 127264.
Vettoruzzo, A., Bouguelia, M. R., & Rögnvaldsson, T. (2023). Meta-learning from multimodal task distributions using multiple sets of meta-parameters. Proceedings of the International Joint Conference on Neural Networks.
Vettoruzzo, A., Bouguelia, M. R., & Rögnvaldsson, T. (2024). Multimodal meta-learning through meta-learned task representations. Neural Computing and Applications.
Vettoruzzo, A., Bouguelia, M. R., & Rögnvaldsson, T. (2024). Personalized federated learning with contextual modulation and meta-learning. Proceedings of the SIAM International Conference on Data Mining.
Vettoruzzo, A., Vanschoren, J., Bouguelia, M. R., & Rögnvaldsson, T. (2024). Learning to learn without forgetting using attention. Proceedings of the Conference on Lifelong Learning Agents.
Vettoruzzo, A., Braccaioli, L., Vanschoren, J., & Nowaczyk, M. (2024). Unsupervised meta-learning via in-context learning. Manuscript under review.